亚搏体育 唐杰的上联, 姚顺雨的下联


agent正在变得越来越颖悟,但它还有一个很难受的问题,那即是干着干着,就忘了我方要干什么了。
长任务、跨会话、连气儿实施,这些确切是agent的发展看法,可前提是它必须有一套可靠的追念系统。不然,再强的模子也只可在一次次对话里反复“重新意志寰球”。
腾讯最近开源的AgentDB,对准的恰是这个问题。
这一个是专门用来惩办追念问题的独处组件,一共独一几MB的大小,下载到电脑以后,在OpenClaw或者Hermes Agent里输入一个请示,AgentDB就装配完成了。
即是这样一个“小玩意”,在发布的同期,腾讯专门为其开设了独处的X账号( @TencentDBAbxo2),并由团队切身在酬酢媒体上与设备者互动。

固然腾讯不同行务皆有X账号,比如混元、腾讯云等等,但这是腾讯第一次为一个开源器用单独开X账号,可见腾讯对这个开源项方针意思意思进程。
那就别说别的了,径直参加主题吧!
01
AgentDB惩办了什么问题?
关于模子追念这个问题,Codex和OpenClaw曾尝试用压缩的格局惩办,把冗长的历史对话压缩成一小段摘录,但这种作念法会不可逆地亏欠追念的细节。
当Agent需要回溯某个具体决策的依据时,那些被压缩掉的信息就长久找不回首了。
这即是传统追念系统的近况。要么把统共历史对话无脑塞进凹凸文窗口,导致token破费爆炸,资本直线飞腾。要么用总结压缩历史,固然省了token,但细节遥远丢失,Agent在需要验证时只可靠迂缓的印象瞎猜。
这两种决策皆不够优雅,也皆不够实用。
AgentDB骨子上是一个分层渐进式的Agent追念管说念系统。它取舍“标记化短期追念+分层耐久追念”的双轨架构,试图在token效力和信息完整性之间找到均衡点。
这套系统的贪图理念包含三个维度。
第一个维度,拒却暴力堆积,也拒却不可逆压缩。
AgentDB贪图了L0到L3四层追念金字塔。L0是原始对话,完整保留每一轮交互的原始记载。L1是提真金不怕火的原子追念,由LLM自动从对话中提真金不怕火结构化事实、用户偏好、任务敛迹和中间论断。L2是场景团员,按任务类型自动归纳计划追念,形成场景块。L3是用户画像,连接提真金不怕火信息,形成领路的耐久用户档案。
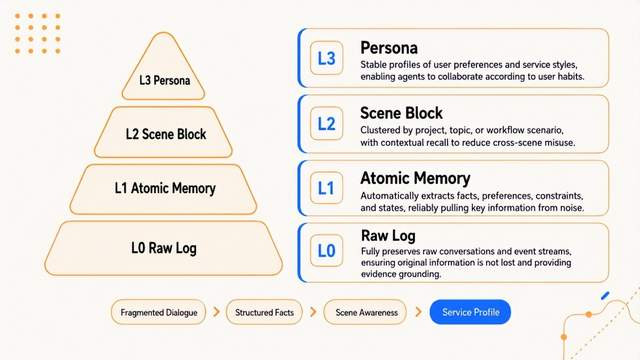
这种分层贪图的中枢价值在于“可压缩、可伸开、可追忆”。
日常Agent责任时,只需要加载高层的Persona和场景块,就能把捏用户偏好和任务条理,token破费极低。当需要验证细节时,再通过索引机制检索底层的原子追念和原始对话,完整还原左证链。通盘过程莫得任何信息被不可逆地丢弃,统共压缩皆是有损但可归附的。
它就像藏书楼相通,把追念放在不同的区域,比如外洋文体、器用书之类。日常为了省时期,只看目次和摘录,需要细节时再去原始记载里找,以保证不丢失信息。
这套机制的施行效果非常权贵。在PersonaMem耐久追念测试中,AgentDB的准确率从传统决策的48%跃升至76%。这使得Agent轻率在跨会话的场景中领路地记取用户的偏好和历史决策,而不是每次对话皆像第一次碰头相通从零驱动。
第二个维度,标记化追念惩办长任务中的信息过载。
在复杂任务中,最破费token的时常不是对话自己,而是那些冗长的中间日记。
搜索限制可能有几千字,代码片断可能有上百行,无理堆栈可能占满通盘屏幕。要是把这些内容沿途塞进凹凸文,token很快就会爆表。
AgentDB的作念法是将这些冗长内容offload到外部文献系统,同期用Mermaid图谱提真金不怕火其中的关绑缚构。注入到Agent凹凸文中的仅仅轻量级的标记化暗意,比如一个任务节点的ID、一段代码的摘录、一个搜索限制的要道词。
当Agent需要回溯细节时,通过node_id精确调回原始文本。这种贪图让凹凸文从“数十万token的日记堆”压缩为“几百token的关系图谱”。
也即是说,AgentDB把大段大段的日记、代码、搜索限制存到外面,只在AI的“责任台”上放一个索引编号和要道词摘录。需要时再根据编号去调取原文。
在WideSearch任务中,这套机制的效果尤其知道。token使用量缩短了61.38%,而任务奏效力反而晋升了51.52%。
这个反直观的限制揭示了一个伏击事实,更多的凹凸文并不老是意味着更好的弘扬。当无关信息稀释了谨慎力时,Agent反而会迷失在信息的海洋中,作念出无理的决策。
标记化追念通过结构化的格局呈现信息,让Agent轻率了了地看到任务的全貌和实施旅途,从而作念出更准确的判断。
第三个维度,全腹地化、零外部依赖。
AgentDB默许使用SQLite加sqlite-vec算作后端,无需并吞任何外部API或云做事。这对企业场景至关伏击。追念数据时常包含敏锐的业务逻辑、用户偏好和名目细节,全腹地化意味着数据主权透顶掌捏在用户手中。
大无数追念系统皆依赖云霄向量数据库或第三方embedding做事,数据必须上传到外部做事器才能使用。
尤其是关于金融、医疗、政务这些行业来说,这种依赖是有问题的,是以这类公司时常皆是独到云,把数据存在腹地里,但腹地的做事器又跑不动大模子。
AgentDB的全腹地化决策惩办的恰是这个问题。
从本领竣事来看,AgentDB的四层追念管线是透顶自动化的。
对话驱动时,系统自动通过向量检索或羼杂搜索调回计划追念,加载用户画像,注入到系统凹凸文中。对话收尾后,系统自动录制对话讯息,双写到IMemoryStore和JSONL文献。
当积贮到一定轮次后,Pipeline调治器轮番触发L1、L2、L3的提真金不怕火和归纳经过。通盘过程对用户和Agent皆是透明的,不需要手动干扰。
你只需要在OpenClaw或Hermes Agent中装配插件,确立好LLM接口,AgentDB就能驱动责任。
统共字段皆有合理的默许值,亚搏(中国)零确立即可使用。关于有非常需求的用户,AgentDB也提供了丰富确切立选项,不错调整每一层的触发阈值、间隔时期、提真金不怕火战略等参数。
AgentDB的另一个亮点是可追忆性。压缩或详细最大的风险是“丢失左证”,当调回的追念出错时,用户只可看到一堆向量分数,无法判断问题出在那里。
AgentDB保留了要道的中间产物算作可读文献。
每一条信息皆100%可找回、可归附,岂论是短期追念中被卸载的一段报错日记,照旧耐久追念里总结出的一条用户偏好,Agent或设备者皆不错沿着“高层标记→中层索引→底层原文”的链路进行齐全溯源与归附。
02
姚顺雨的“凹凸文表面”找到了最好实践
AgentDB这个产物,某种进程上来说,即是腾讯对姚顺雨“凹凸文表面”的一个落地决策。
姚顺雨此前屡次强调,AI的中枢才智不在于参数限度,而在于对凹凸文的并吞、管束和期骗。
这个不雅点在他加入腾讯后发布的第一个模子Hy3 preview中,得到了充分体现。
Hy3 preview这个模子最稀薄的方位在于,它把“出色的凹凸文体习和请示解任才智”单独拎出来,写进了中枢才智清单的第一条。
当其他厂商皆在卷agent才智、代码生成、多模态的时候,Hy3把凹凸文才智放在了最显眼的位置。
姚顺雨加入腾讯后发布的第一个询查后果是CL-bench,这是一个专门用来测试模子能否从凹凸文中学习新常识并正确应用的基准。
在Hy3 preview的性能展示中,第一张图放的不是SWE-Bench Pro或者Terminal-Bench 2.0这种agent和代码榜单,而是AdvancedIF、AA-LCR,以及CL-bench这些看凹凸文推理、检索和请示解任的榜单。
腾讯觉得凹凸文管束才智,才是AI下一阶段赛说念。
其实市面上有不少模子厂商皆会在宣传时皆会强调我方扶植多长的凹凸文,包括OpenAI和Anthropic,从一驱动的32K到128K,再到1M以至微软也曾提到过的10M凹凸文。
但你实在用的时候就会发现,凹凸文越长,模子的弘扬时常越差。
信息密度被稀释,谨慎力被散播,模子在海量的无关信息中迷失看法,反而作念出更多无理的决策。
姚顺雨团队的消融实验验证了这个不雅点,无关信息会稀释了谨慎力。这亦然AgentDB的分层贪图想要去惩办的问题。
腾讯为AgentDB专门开设X账号,并由团队成员主动发起AMA,这在腾讯的开源名目中并不常见。这种高调姿态背后,是腾讯但愿将AgentDB打形成“凹凸文管束”界限标杆的计议。
但是AgentDB现在在实战这块并莫得很拉风的弘扬,腾讯需要给AgentDB“带货”。
AgentDB的价值需要通过具体场景才能被感知。
比如,腾讯不错拿出混元模子,聚积AgentDB构建一个“连气儿责任30天不丢失凹凸文的代码审查Agent”,或者“记取用户统共偏好的个性化内容保举Agent”。
独一当设备者看到“某个模子+AgentDB”产生的化学响应,群众才会去用它。
03
唐杰的“上联”,姚顺雨的“下联”
就在AgentDB发布前夜,智谱独创东说念主唐杰夜深发布了一条长文反念念,中枢不雅点直指,长周期任务将是本年AI最可能的打破点。
唐杰觉得,AI的实在价值不在于单轮对话的智能,而在于通过与环境连接交互,完成复杂、延展的任务。

他举了一个黑客的例子,一个能24/7不阻隔搜寻软件破绽的AI,骨子上是在学习黑客的高阶直观和方法论,而非陋劣的搜索。
这种“长周期学习+连接实施”的才智,才是下一阶段AI所需要的。
而要竣事长周期任务,唐杰指出了三大本领支撑,追念、连接学习、自我判断。
其中,追念被他列为“通过奥妙工程妙技起初被惩办”的才智。
这个判断和AgentDB的产物逻辑险些是重合的。
要是说唐凸起了一个“上联”,“长周期任务需要追念算作前提”,那么腾讯用AgentDB对了一个“下联”,“分层追念让长周期任务成为可能”。
Agent需要记取我方作念了什么,为什么这样作念,接下来该作念什么。要是每实施几步就健忘之前的决策,那么长周期任务根蒂无法完成。
更故理由的是,唐杰还在文中提到了“自我判断”才智,固然AgentDB体积很小,但它的架构中也允许AI进行“自我判断”。
当Agent轻率通过Mermaid图谱了了地看到我方的任务进展、通过分层追念回溯历史决策,它就具备了“元瓦解”的基础。
知说念我方作念了什么、为什么这样作念、接下来该作念什么。
这种结构化的自我瓦解,恰是自我判断的前提。
从这个角度看,AgentDB不仅是一个追念系统,更是腾讯对“长周期任务期间”的一次本领押注。
唐杰刻画了愿景,腾讯拿出了器用。
而在这场“长周期竞赛”中,追念系统即是Agent的燃料箱。容量决定续航,结构决定效力。
AgentDB的开源,意味着腾讯把这个燃料箱的贪图图纸公开了,何况照旧免费的。
智谱在长周期任务上照旧有了一些初步的后果。在GLM-5.1的白皮书中提到,GLM-5.1在不需要任何东说念主工干扰的前提下,轻率连接功课8小时。
但这仅仅一张收获单,要实在让企业宽解,还得看它在更多场景里会不会掉链子,遭遇没见过的问题时能弗成靠我方的妙技惩办。
长周期任务不是一个通用产物,它需要针对不同行业、不同场景作念深度定制。
这亦然AgentDB的契机所在。
算作一个独处的追念组件,AgentDB不错和任何模子、任何Agent框架集成。智谱不错用,字节不错用,阿里也不错用。
这种绽开性让AgentDB有契机成为长周期任务的基础门径。
而长周期任务也不是某一家公司的专利,是通盘行业的共同看法。谁能开首在这个方进取赢得打破,谁就能鄙人一轮竞争中占据先机。
而在这场竞赛中,追念管束才智将是决定性的身分之一。
腾讯把这套决策开源出来,既是一种本领自信的展示,亦然一种对生态确立的投资。
要是AgentDB轻率成为长周期任务的方纲追念组件亚搏体育,那么腾讯在这个界限的影响力就会远远超出一个开源名目自己。